

Modern AI agents have become increasingly adept at accessing files and tools to retrieve information — from searching via the web and MCP, to editing code with Bash and Unix tools, to more advanced use cases such as editing memories and loading “skills”. A critical challenge is determining what information should be in the agent's context window at any given time: too much information can cause context rot, while not enough information can cause hallucinations and poor performance. "Agentic context engineering" is when agents themselves (rather than humans) strategically decide what context to retrieve and load to accomplish a task.
Agentic context engineering is the new frontier in AI agents. Models that are post-trained specifically for context engineering will excel at long-horizon tasks where the task length far exceeds the native context windows of the LLMs themselves. So which models do it the best?
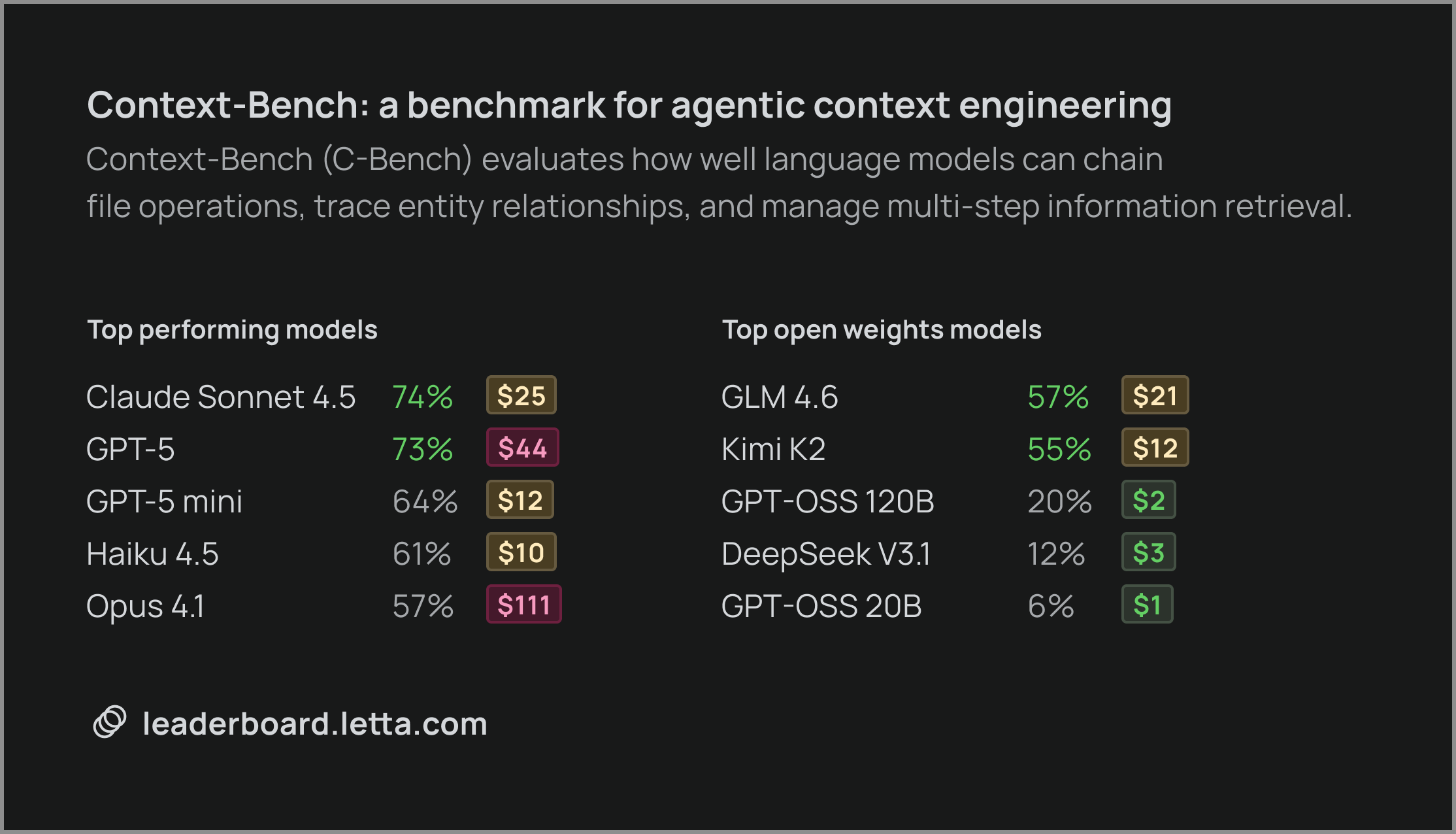
To answer this question, we are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.
Context-Bench proves promising for the open source community: the gap between frontier open weights models and closed weights models appears to be closing. Unsurprisingly, frontier closed models that have been explicitly trained for context engineering such as Sonnet 4.5 still top the current leaderboard.
Introducing Context-Bench
Context-Bench measures an agent's ability to perform context engineering. Our goal is to construct a benchmark with the following properties
- Contamination Proof. Questions are generated from a SQL database with verified ground-truth answers, and all entity names and relationships are completely fictional to ensure models cannot rely on training data.
- Multi-Hop / Multi-Turn Tool Calling. Designed to require multiple tool calls and strategic information retrieval—agents cannot answer correctly without navigating file relationships.
- Controllable Difficulty. Unlike benchmarks that are quickly saturated, we can control the difficulty because the questions are generated from SQL queries. We can update the difficulty of the queries by changing the complexity of the SQL query to generate more challenging versions of the benchmark for future models.
Constructing Context-Bench
First we start by programmatically generating a database with facts about various entities with relationships between them e.g. people, pets, addresses, medical records. We then use an LLM to generate challenging, but tractable SQL queries against the database. Specifically, the question generator:
- Explores the database schema and considers the existing question corpus
- Ideate on a potential question by generating queries against the database
- Executes the queries to get the answers
Given the SQL queries and the execution results, we then use an LLM to convert these to natural language queries, and convert the structured database into semi-structured text. Questions in Context-Bench require the model to search through multiple files and understand the relationships between many large sets of facts. For example, agents might need to:
- Find information about a person, then locate a related project, then identify a collaborator
- Search for a specific attribute, verify it across multiple files, then trace connections to related entities
- Navigate hierarchical relationships to answer questions about indirect connections
- Compare many different sets of items and compare and contrast their attributes
Evaluating Agents on Context-Bench
To evaluate their ability for general-purpose context engienering, agents are given two tools:
- open_files: Read the complete contents of a file
- grep_files: Search for specific patterns within files
Context-Bench measures the ability of agents to:
- Construct effective search queries
- Chain file operations to trace relationships
- Choose the right tool (grep vs. open)
- Navigate hierarchical data efficiently
We track the total cost to run each model on the benchmark. Cost reveals model efficiency: models with higher per-token prices may use significantly fewer tokens to accomplish the same task, making total cost a better metric than price alone for evaluating production viability.
Models Trained for Context Engineering Excel
Claude Sonnet 4.5 leads the benchmark with a 74.0% score at $24.58, demonstrating exceptional ability to navigate complex information retrieval tasks. This model shows strong reasoning about what information to retrieve and how to chain lookups effectively. GPT-5 scores 72.67% at $43.56, showing competitive performance but at nearly twice the cost of Claude Sonnet 4.5. GPT-5-mini delivers solid performance at 64.33% and $12.45, making it an attractive option for cost-sensitive deployments.
Open-Weight Models Closing Gap to Closed-Weight Models
One of the most encouraging findings is that open-weight models are rapidly catching up to proprietary models in context engineering capabilities:
- GLM-4.6 from Zhipu AI achieves 56.83%, demonstrating that open-weight models can handle complex multi-step retrieval tasks.
- Kimi K2 scores 55.13% at just $12.08, offering the best cost-per-point ratio among open-weight models and proving viable for production deployments.
Challenges Remain: Agentic Context Engineering as a New Frontier
While progress is encouraging, the benchmark also reveals areas where models struggle:
- Nano models (GPT-4.1-nano at 16.2%, GPT-5-nano at 44.83%) show that smaller parameter counts still significantly impact complex reasoning
- DeepSeek V3 (11.97%) and the GPT-OSS models (6.67% - 20.2%) demonstrate that not all open-weight models have achieved breakthrough performance
- Even top models miss 25-30% of questions, indicating substantial room for improvement
Key Takeaways
- Models trained for context engineering, eg. Claude Sonnet 4.5 are recommended drivers production agents requiring strong context engineering, offering the best balance of performance and cost.
- The gap between proprietary and open-weight models has narrowed significantly. GLM-4.6 and Kimi K2 demonstrate that open-weight models can now handle complex agentic tasks, making them viable for many production use cases.
- Context engineering remains challenging. Even the best models achieve only 74% accuracy, highlighting the complexity of multi-step information retrieval and the opportunity for continued improvement.
What's Next
We're actively updating Context-Bench as newer models are released and will be expanding the benchmark with more tasks, particularly around continual learning tasks. We welcome community contributions to Context-Bench! Context-Bench is built on the open source Letta Evals framework.
To learn more, check out:
- The live-updated Context-Bench leaderboard: https://leaderboard.letta.com
- Letta Evals documentation: https://docs.letta.com/evals
- Letta Platform: https://app.letta.com